Lab 5:
Win, Place, LQR
Please Log In for full access to the web site.
Note that this link will take you to an external site (https://shimmer.mit.edu) to authenticate, and then you will be redirected back to this page.
Quick Reference
Serial Plotter Send Window Indices

Useful Offsets to Set
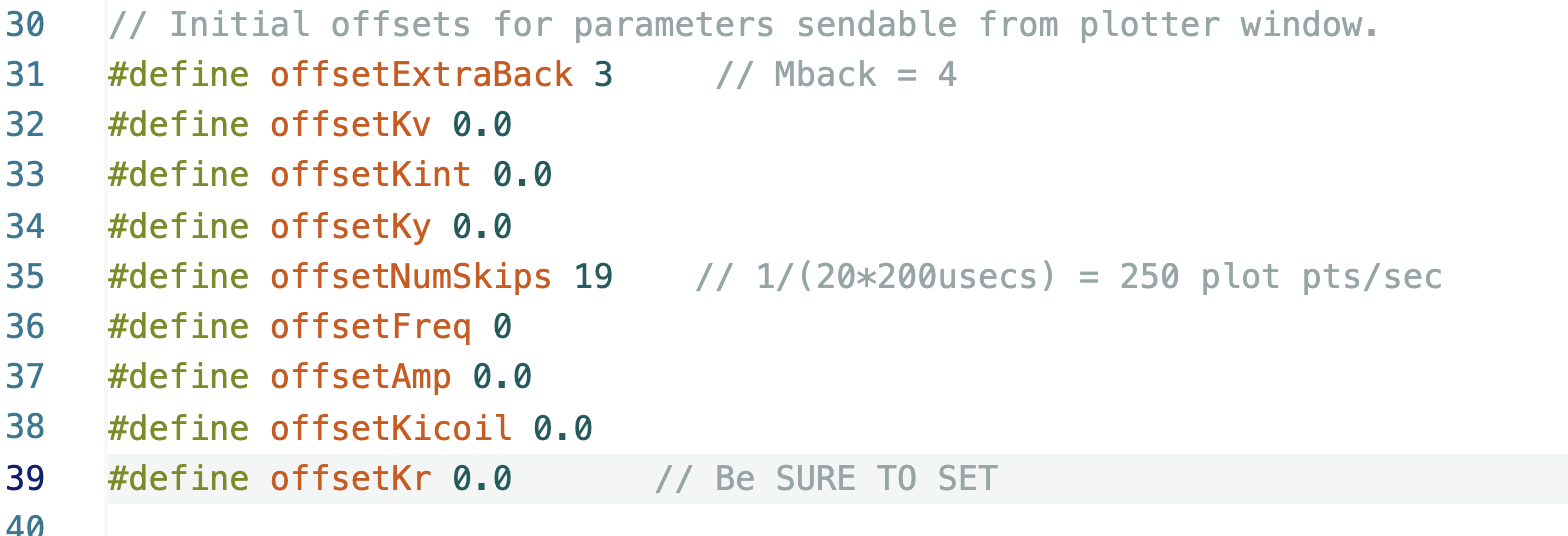
Links
- New sketch for this lab is here.
- New matlab script for this lab is here. Or if you prefer a colab notebook (here).
Calibration
Download this week's sketch and update the system parameters in this sketch to match your system as follows.
- Set the optical sensor parameters (
SensorScaleandSensorOffset). You can transfer the values from last week's sketch, but you should check the result by verifying thatDY_mis-1500,0, or1500when the umbrella is in the top, middle, or bottom reference positions. - Check the polarity of all three coils using a compass. If they are different, make them match by changing the parameters in lines 179-182 of the sketch.
- Check the polarity of the coil currents by viewing
CrntandCmdwhile disabling the other traces. Turn the pot back-and-forth from fully clockwise to fully counterclockwise. IfCrntsteps up whenCmdsteps up (left panel below), thencrntSignis correct. If the steps are in opposite directions (right panel below), change the sign ofcrntSignin line 14 of the sketch.

- Set the operating point for the magnetic field as follows.
Set
Ky(index 3 in the send window) to 5 andKr(index 8) to 5. Then find a value ofKv(index 1 in the send window) and a setting for your offset potentiometer so that your umbrella is suspended stably at distance zero.Kvnear 0.1 should work.
DEBUG TIP: If your umbrella is not levitating, you may need to change the directions of all the coils, i.e. switch B1L with B2L, A1L with A2L, A1R with A2R, andB1R with B2R in lines 178-182 of the sketch. - Set the current offset (
crntOffset) on line 15 of the sketch so that the coil current (Crnt) displayed on the plotting window is near zero. The resulting value for the offset should be between 0.2 and 0.8. - Save a screen-shot of the plotting window showing
dY_d,dY_m, andCrntwhile the umbrella is hovering atdY_dnear 0.
Kv and crntOffset?

Transferring to States
In this lab, you will be designing state-space controllers for your Maglev system, but you will not be starting over, as we hope to make clear in this section.
The Ins and Outs
In order to design a better-than-PD controller for our maglev system, we needed an accurate model. We used a combination of analysis and measurement to determine a transfer function model for the system, or more specifically, for the green encapsulated region in the maglev system diagram below.
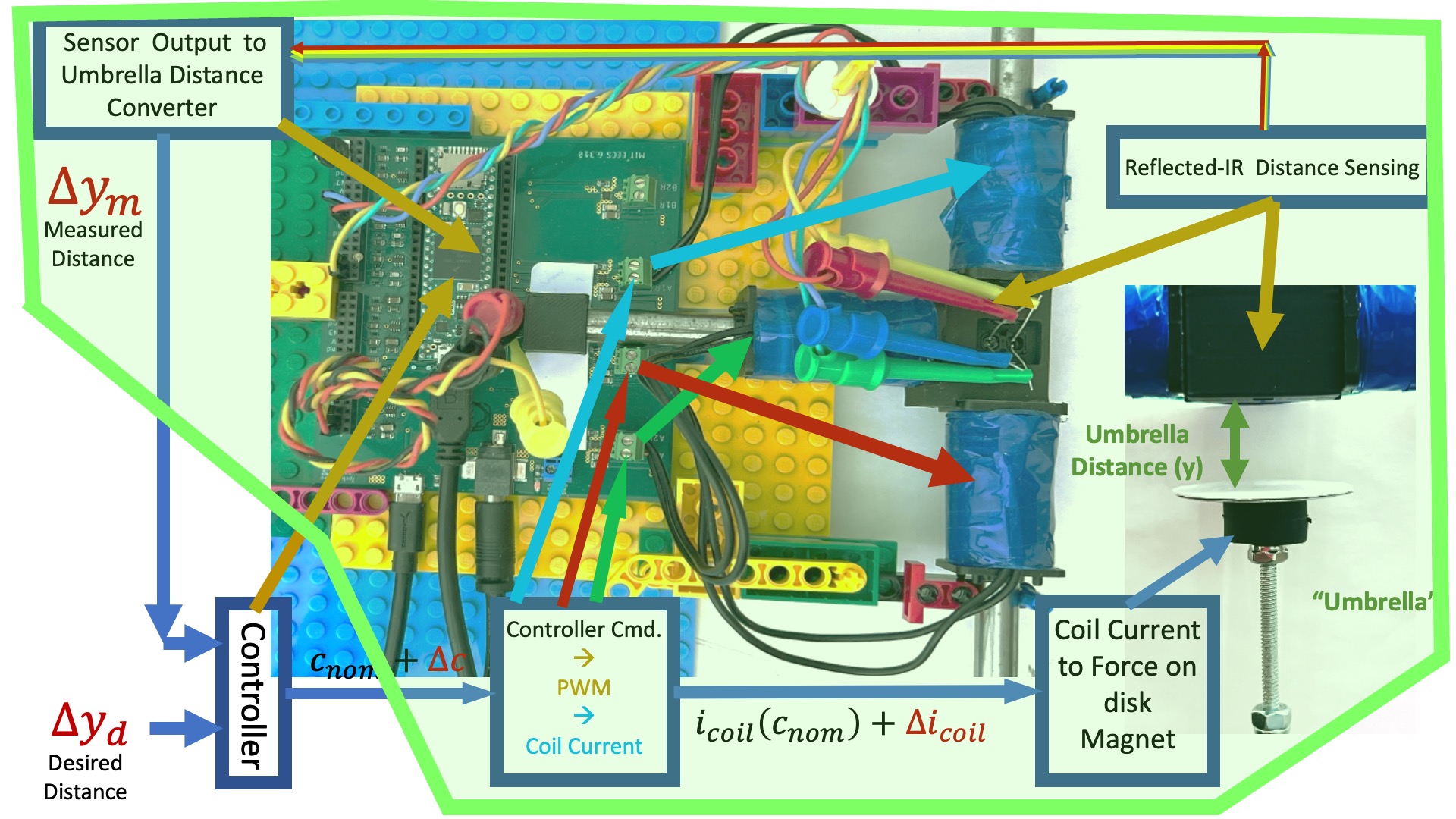
The single-input single-output maglev transfer-function model is shown in the block diagram below (and labeled H_{c2y}(s)), where it is combined with a "lead" controller, labeled K(s), and embedded in an umbrella-position-controlling feedback system.
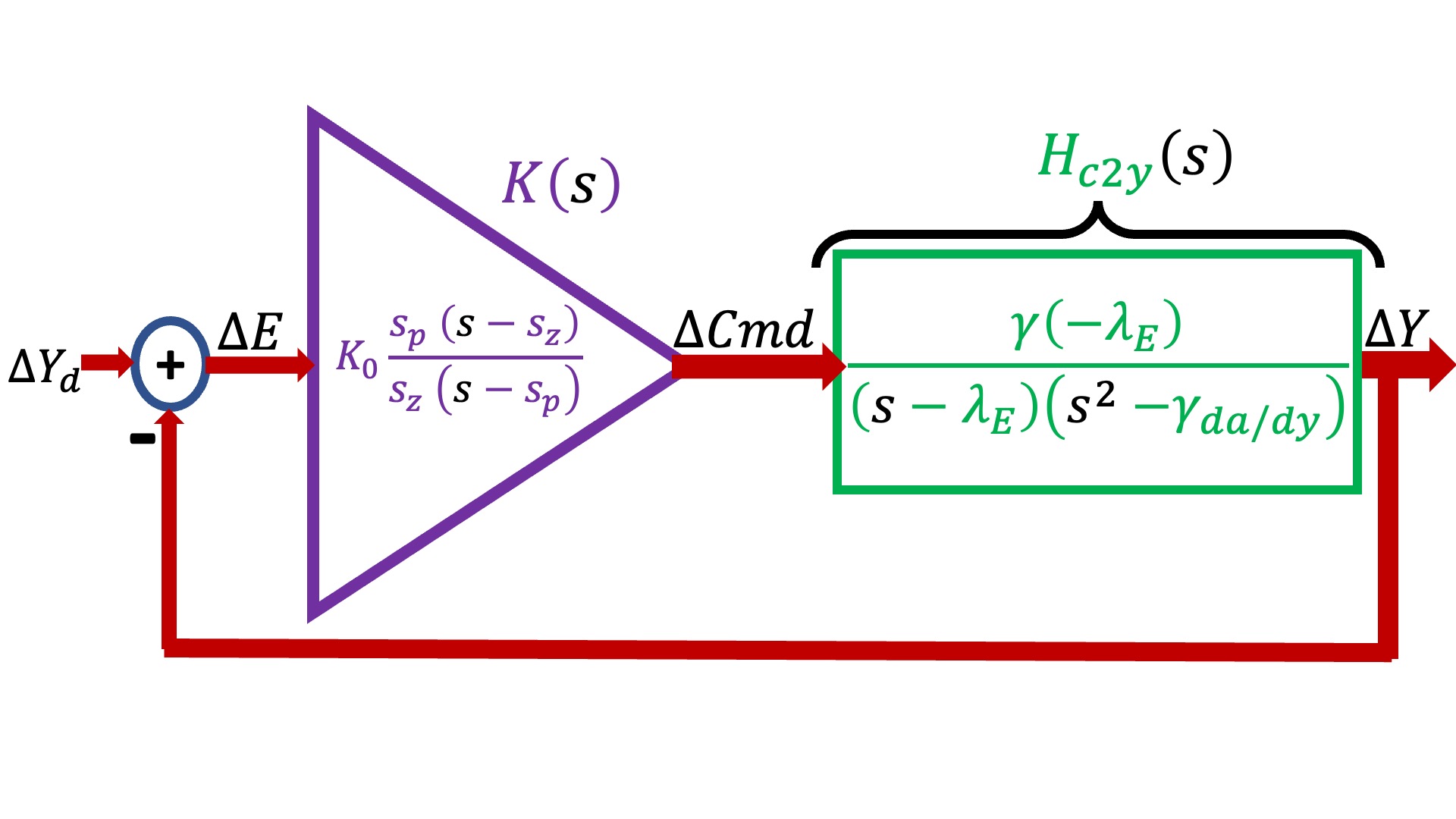
In the above block diagram, the maglev model (in green and labeled H_{c2y}(s)) has three model parameters, \gamma, \lambda_E, and \gamma_{\frac{da}{dy}}, and the lead controller (in purple and labeled K(s)), has three design parameters, s_z, s_p, and K_0. In the last lab, we used a variety of measurements to determine H_{c2y}(s)'s model parameters, and then used that calibrated model (along with the concept of phase margin) to determine K(s)'s design parameters.
State-ing the Obvious
We are using an optical sensor to estimate umbrella position, are using its sample-to-sample variation to estimate time derivatives, and are using a magnetic field sensor to estimate coil currents. Effectively, we are measuring the umbrella's state: its position, its velocity, and its acceleration (coil current is proportional to force, force is proportional to acceleration). Yet we are not using state-space control, we are not even using all the states we can measure. Coil current is ignored by our PD and lead controllers, its measurements are only being used for model calibration.
As an alternative, consider the system diagrammed below, in which the controller uses measurements of coil current, umbrella velocity and umbrella position to determine command updates to the coil driver.
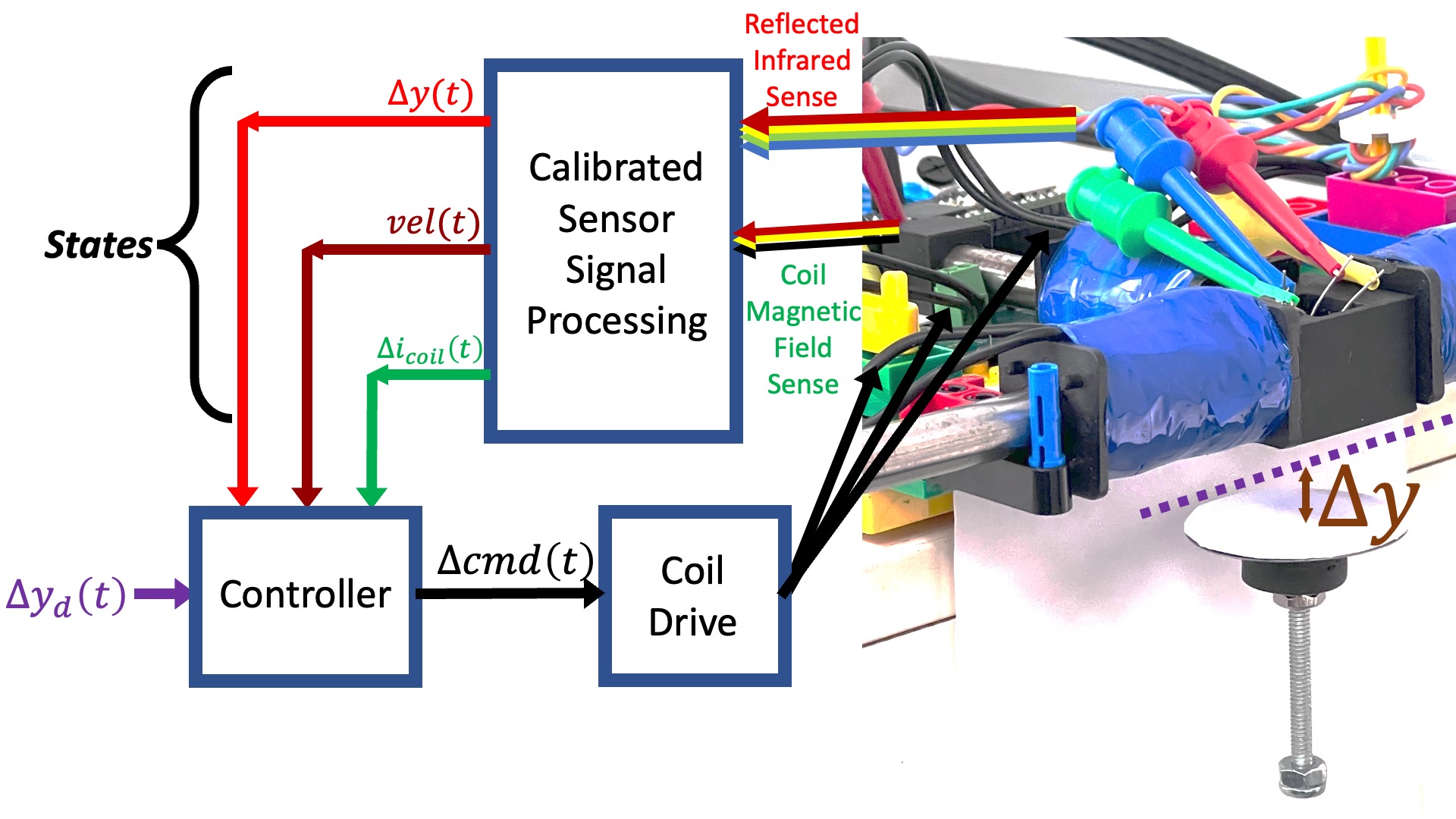
We could then use a linear state-space controller, like in the figure below.
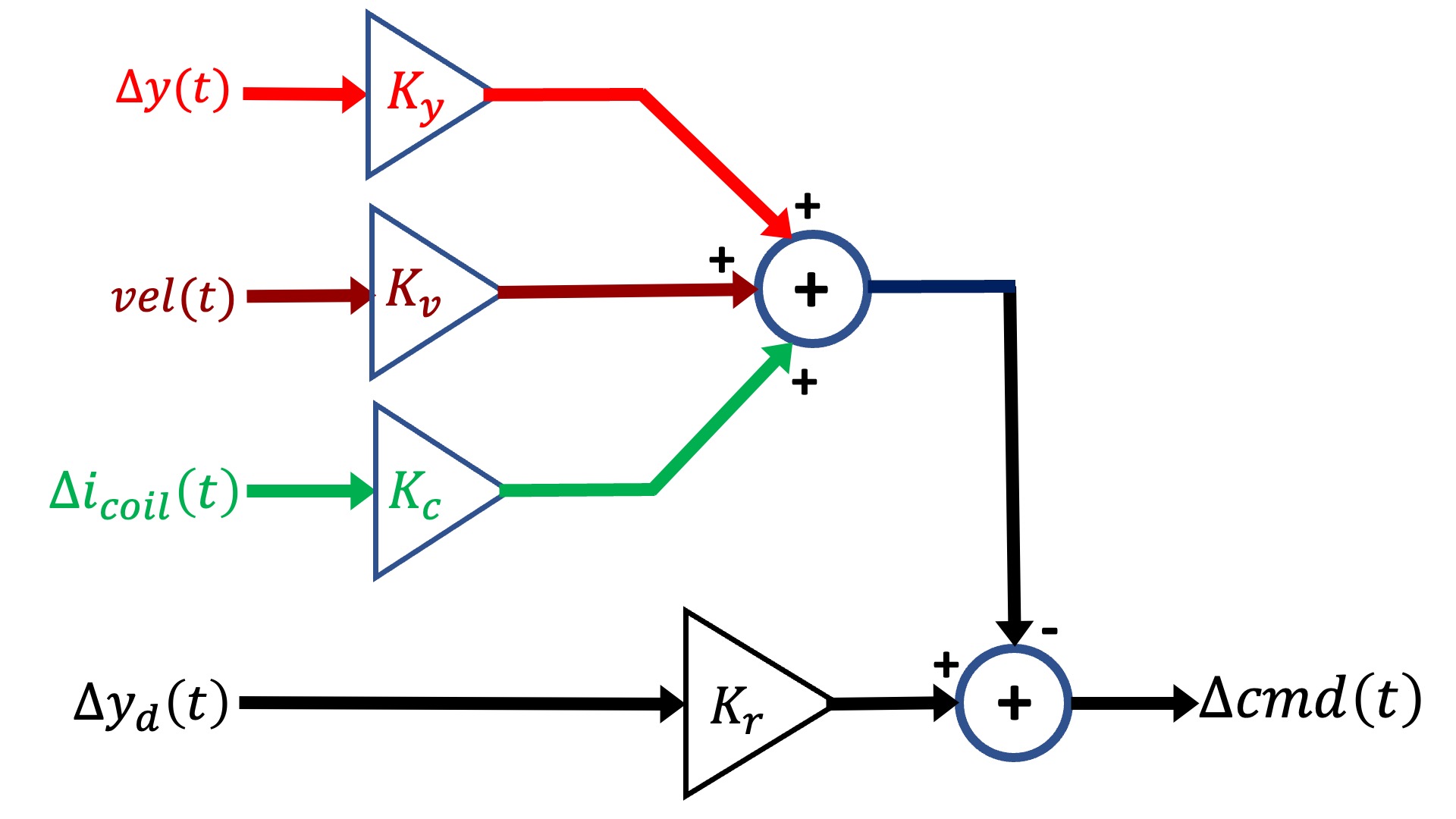
It was difficult enough to design the lead controller when we only had three parameters to determine, s_z, s_p, and K_0. And as the above diagram makes clear, we now have four, the three state "gains", K_y, K_v, K_c, and the input scaling, K_r. Luckily for us, there are computational tools that will help us find reasonable values for the K's, given a state-space model for our system.
State-Space
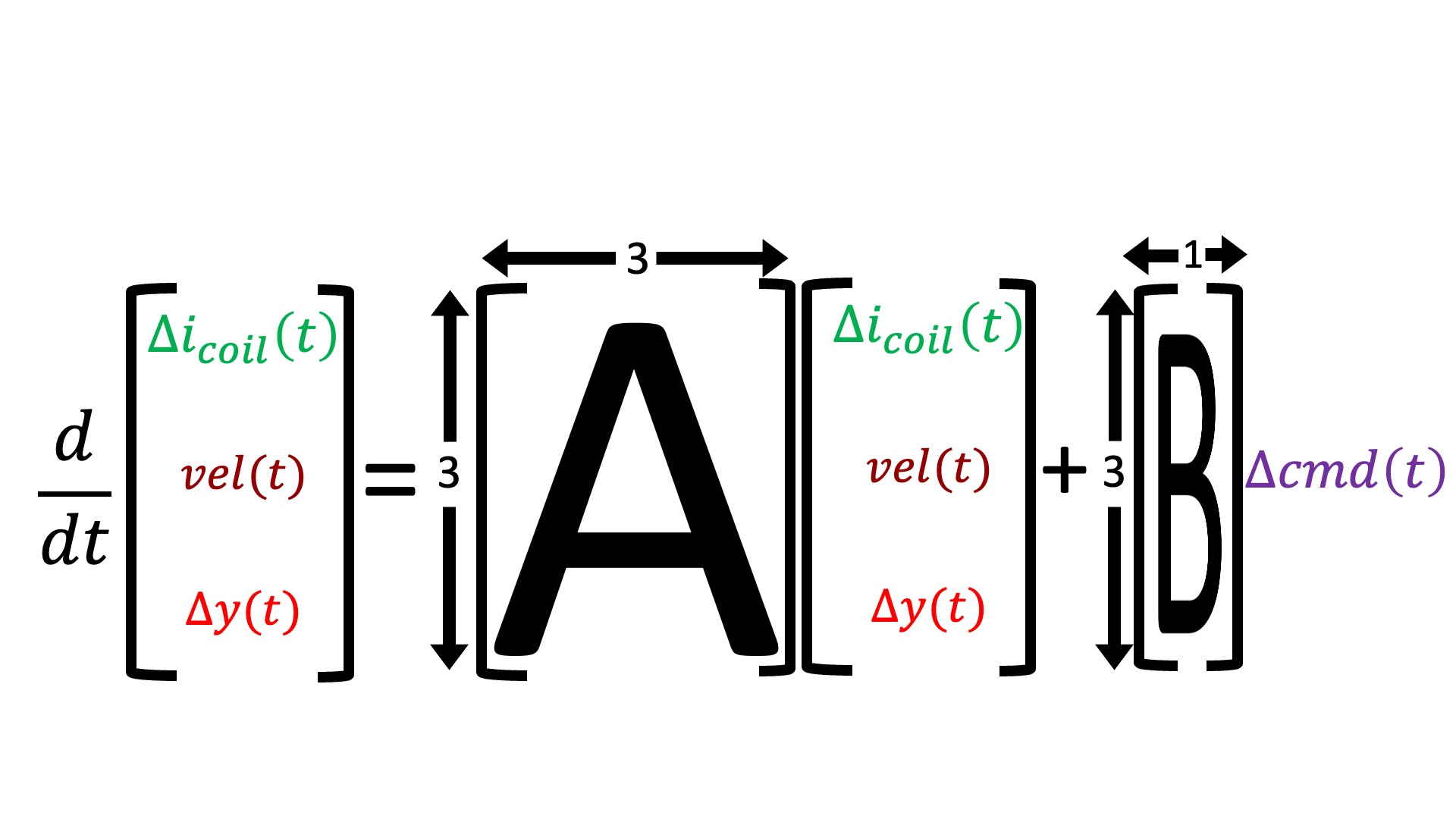
Consider the state-space model differential equation,
We summarize system with the states and matrices below.
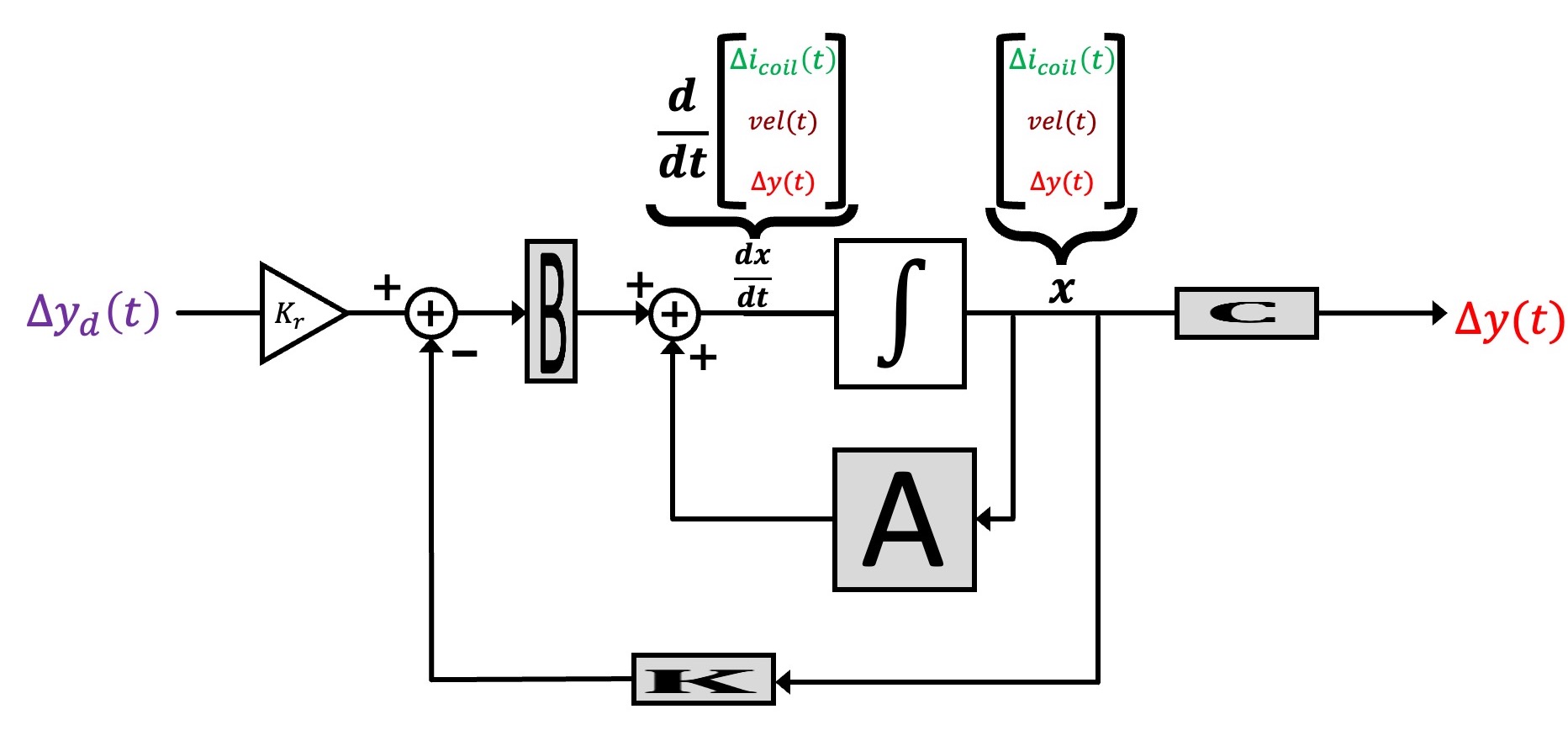
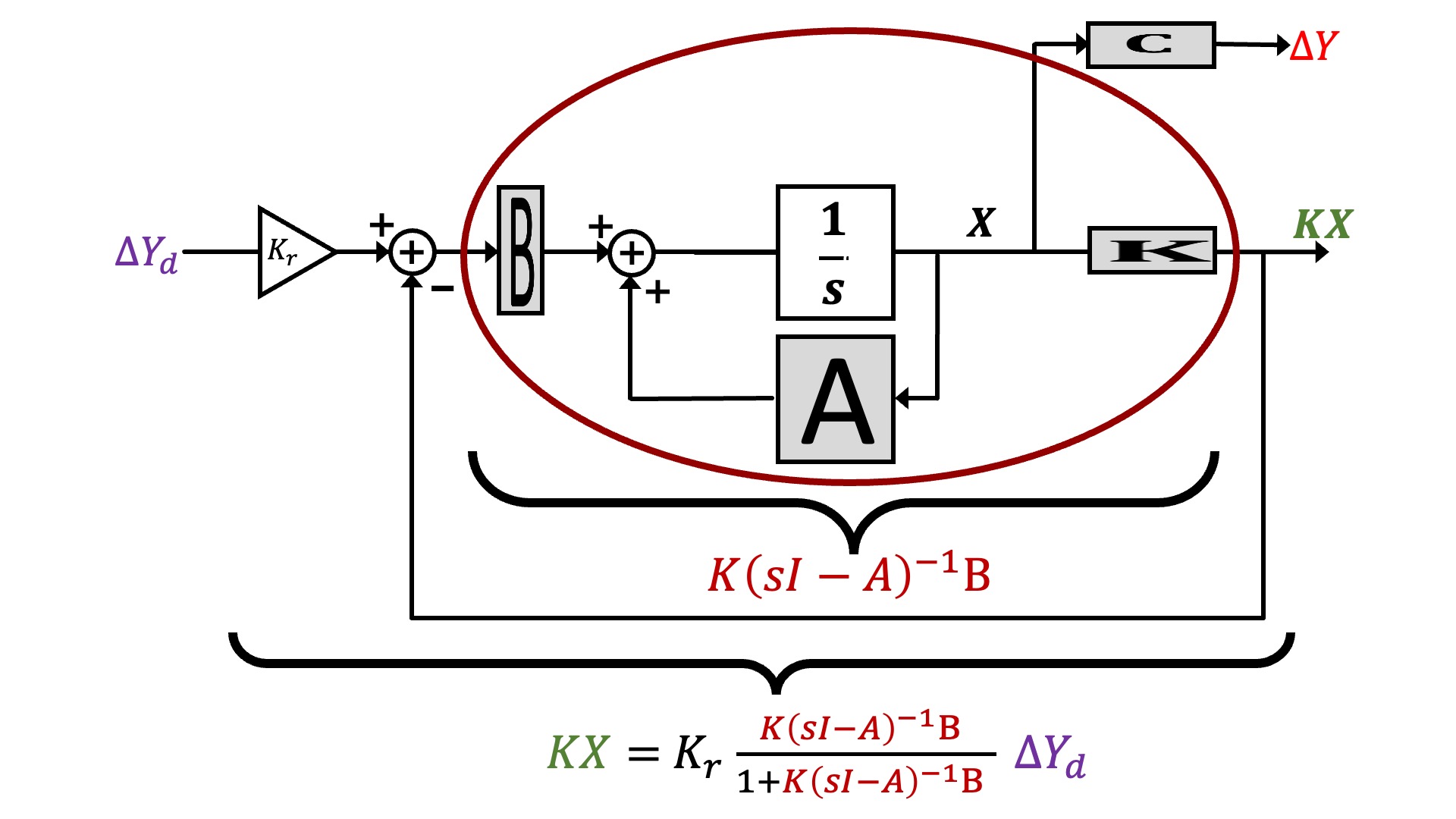
In standard state-space feedback, u(t) = \Delta cmd(t) is given by a scaling of a desired input, K_r \Delta y_d(t), minus feedback from a weighted combination of the states, -K x(t), as shown in the block diagram below.
We can represent the block diagram in transfer function form, as shown below.
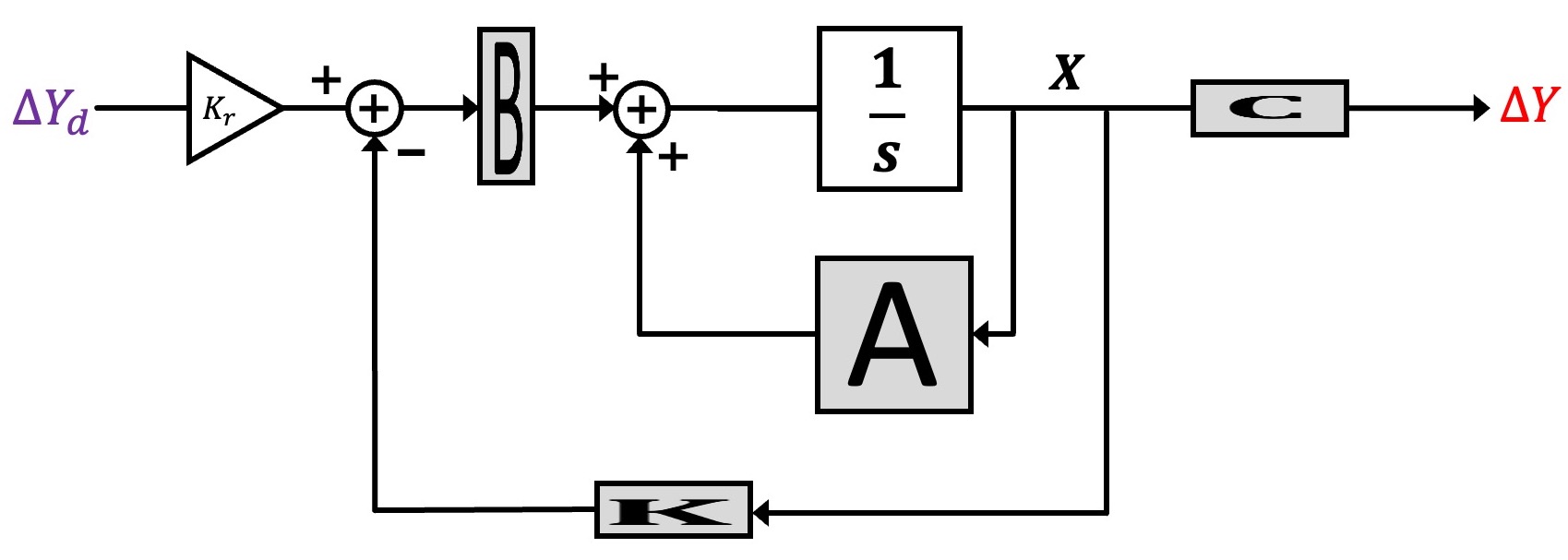
And finally, we can reorganize the state-space description to make its description look more like the feedback loops we have been analyzing with Black's formula, as shown below.
Consistent States
Fortunately, in the last lab we created and carefully-calibrated a model of our maglev system, but unfortunately, the model is in transfer-function rather than state-space form. And transforming the transfer-function model to a state-space model requires that we pick states consistent with our measurements. Tackling this problem will be this lab's first challenge.
Determining and testing the state-space model.
What we need is a state-space model whose states are consistent with our measurement of umbrella position, umbrella velocity, and coil current. That is, we must find an \{A,B,C,D\} state-space model for our maglev system that satisfies two criteria:
- its states are umbrella position, umbrella velocity, and coil current;
- its transfer function matches the our carefully-calibrated maglev transfer function.
The First Row
To start the process of mapping the transfer function into the A and B matrices in the above figure, consider unraveling the H_{c2y}(s) transfer function back into a product of two transfer functions, one from Teensy command to coil current and one from coil current to umbrella position as shown below.
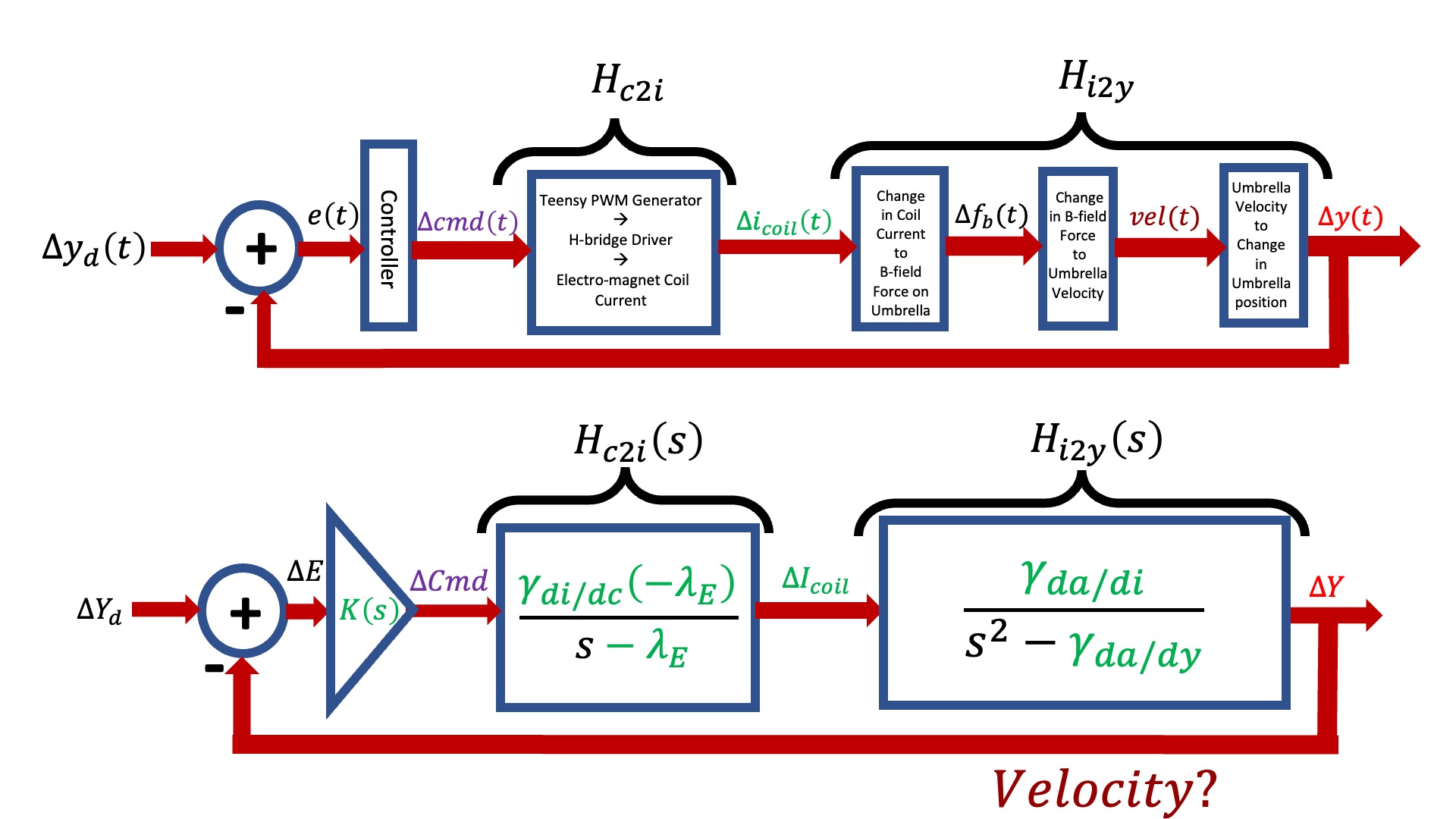
As noted in the above figure, we now have an explicit \Delta I_{coil} and an explicit \Delta Y that correspond to the first and third states, but we do not have anything explicit relating to velocity. Nevertheless, from H_{c2i}(s) we can determine the differential equation that relates Teensy command to coil current, and map its coefficients into the appropriate matrix elements in the first row of A andB, as shown in the figure below.
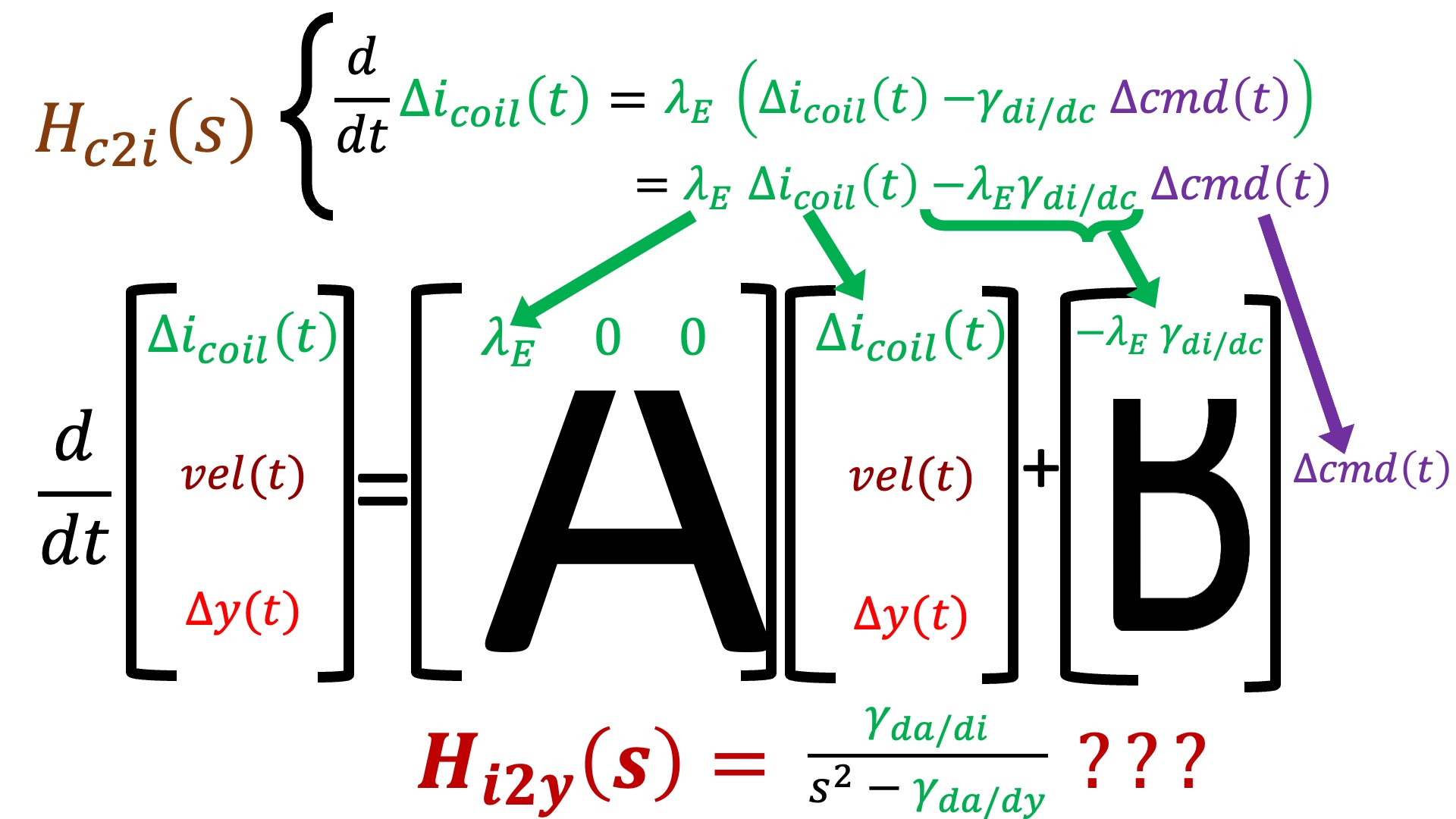
In the above two figures, we noted that velocity is missing in the transfer function and H_{i2y}(s) is unused in constructing the state-space model. How might we incorporate this unsed information to fill in the bottom two-thirds of A and B?
BONUS TIP: There are a few tricks to converting transfer functions to state-space models, a nice example is given here.
The Matlab/Python Script
We have provided a Matlab/Python script with the structure of a state-space model for maglev. To use the script to model your hardware system, you will have to provide values for several parameters, including \lambda_E, \gamma_{da/dy}, \gamma_{da/di}, and \gamma_{di/dc}. You have already measured these parameters in last week's lab. You found \lambda_E and \gamma_{di/dc} in Checkoff 5. And you found \gamma_{da/di} (which is the same as \gamma/\gamma_{di/dc}) and \gamma_{da/dy} in Checkoff 6.
Take some time to examine the script and make sure you understand what each part is doing.
Note that we created a system with multiple outputs, defined by the matrix Cplot in the matlab script. We did this so that when we used the step (Matlab) or analogous Python command, plots of all three states are generated, not just position. But we also want to plot one more quantity. Recall that u = K_r y_d - K x, and that in our case, u = \Delta cmd, and its plot should not exceed 10 by much, or be much smaller than -10 (\Delta cmd will saturate the coil driver if outside the range -1 to 1, and we scale that by 10 because the script is simulating a unit step, and we typically take steps of 0.1). The step function will plot u = K_r y_d-K x if we prepending a row to the Cplot matrix and add a single non-zero value to a 4 \times 1 Dplot matrix.
For state-space models, D is used to represent a direct contribution of system's input to its output, as in
Modeling and Matching (Checkoff 2)
Please use your insight into state-space modeling, along with the hints above, to find and fix all the TODO: (Checkoff 2) sections of the Matlab/Python script linked at the top of this page. If you have implemented a reasonable state-space model and set values for K and K_r that produced oscillations with your PD maglev controller from last week, then after running the script you should see four plots. From top to bottom they are: the Teensy command being sent to the maglev coil drivers, i_{coil}, vel and y.
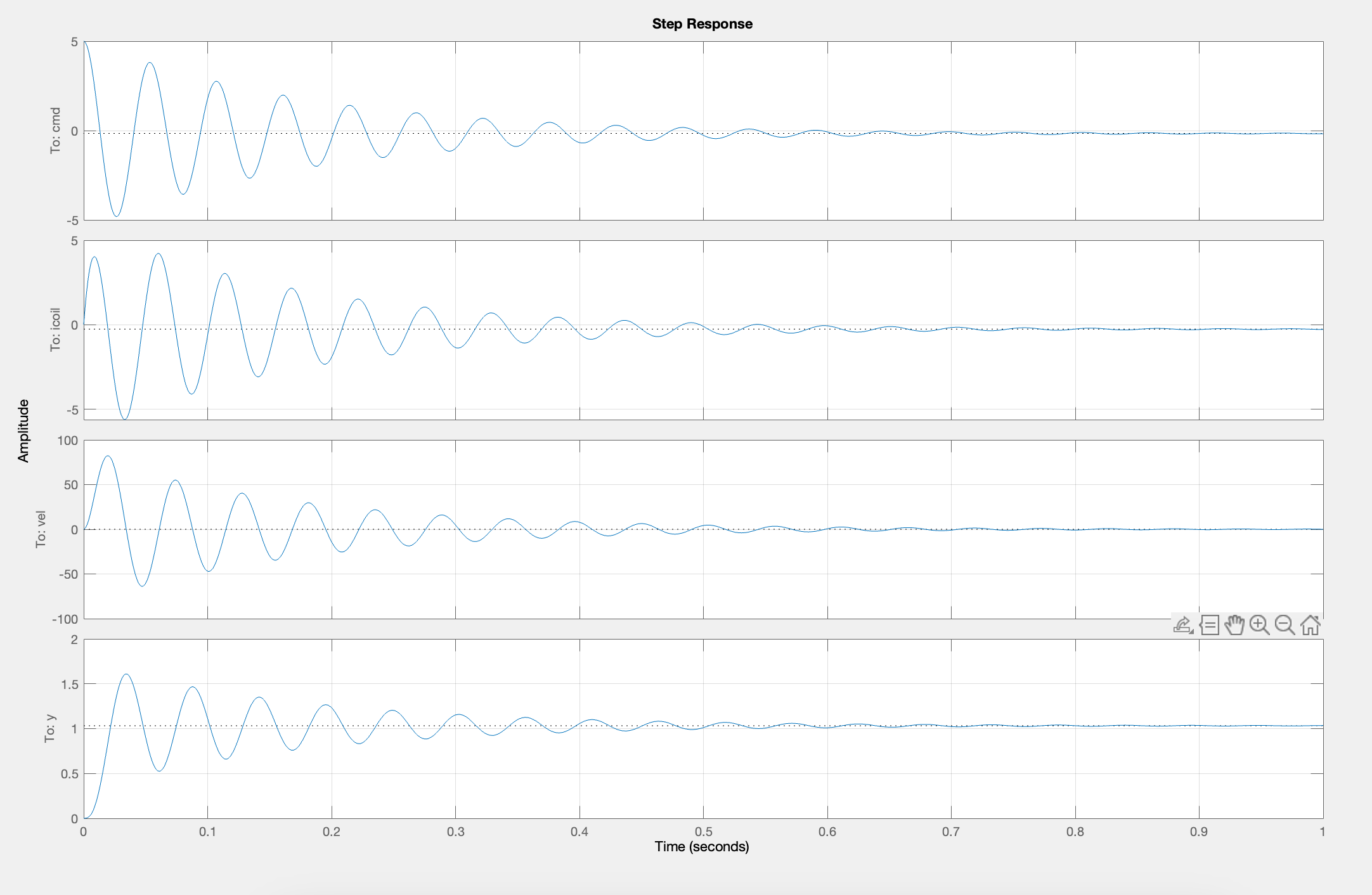
Once you have the script producing reasonable outputs, plug in both board power supplies, connect your laptop to the Teensy, and upload the 6310_MAGLEV_24_SS Teensy sketch (linked above), and start the serial plotter. When you start the serial plotter, you should see a plot of six waveforms (this time starting from the bottom and working up): \Delta y, the umbrella position; \Delta y_d, the desired position; vel, the umbrella velocity; Crnt, the electromagnetic coil current; Cmd, the Teensy command to the coil driver; and intErr, the integral of the position error. A typical plot snapshot is shown in the figure below. Notice that the controller update period is 200\,\mus and numSkips starts out as 19. Therefore, there are 250 plotted points per second by default.
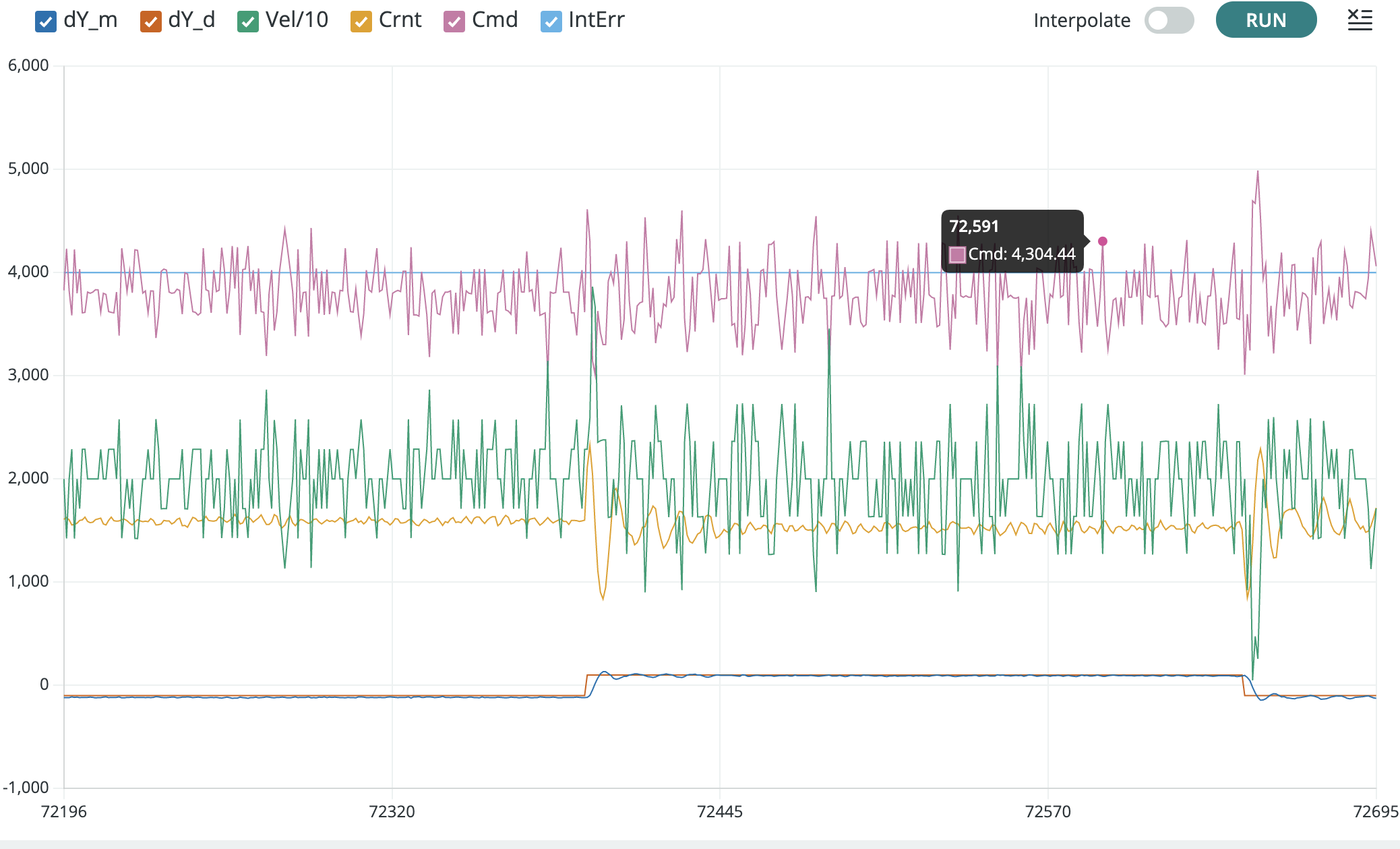
In the Teensy serial plotter, you can unclick all but \Delta y and \Delta y_d, to focus in on position errors, as shown below.
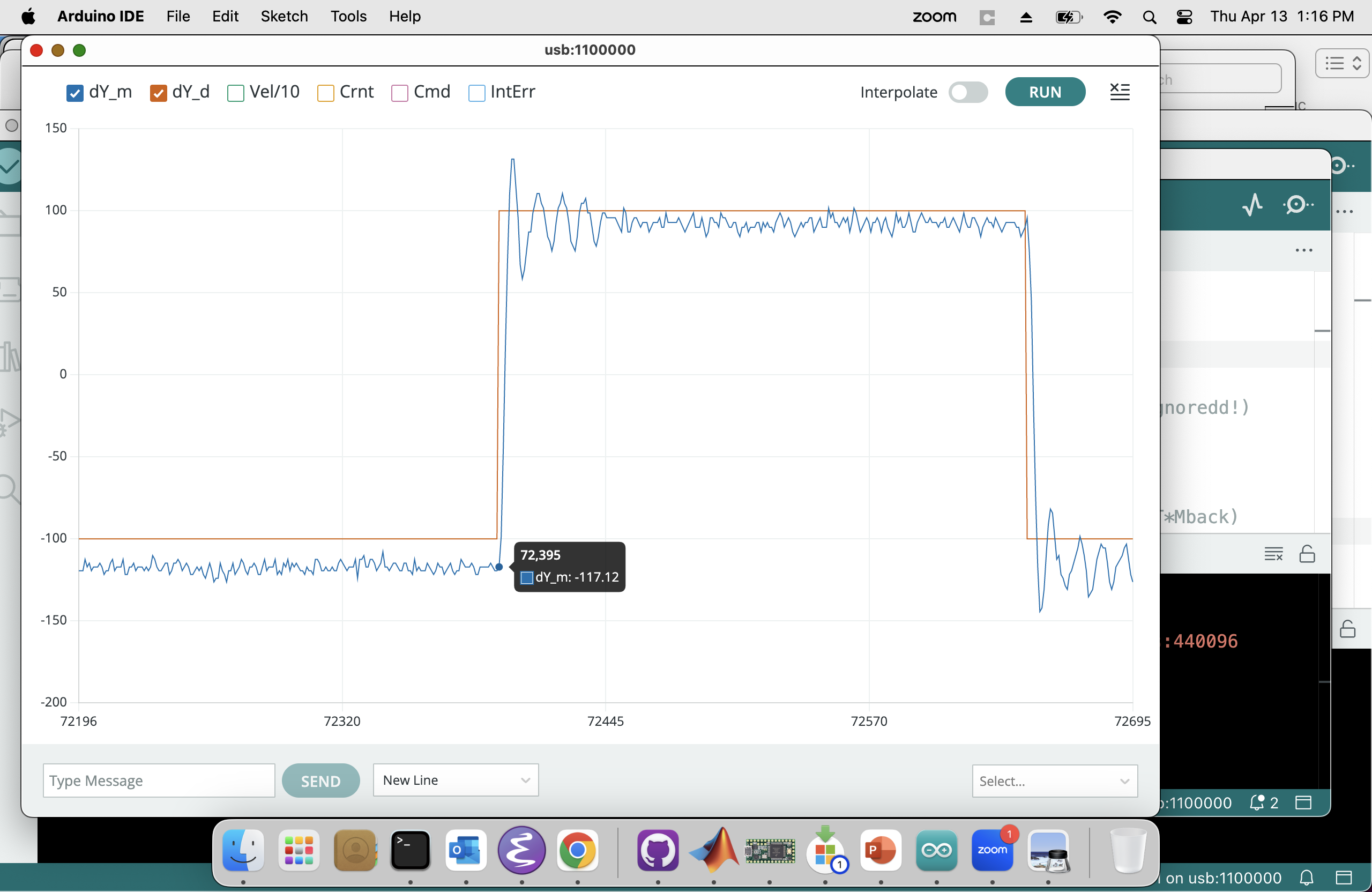
Or unclick all but Crnt to focus in on the coil current scaling, as shown below.
Now if you set the same K and K_r on your lab system, you should be able to compare the plots from the Teensy serial plotter to the simulation outputs from the script. If your model is a good match, then you should see results like the ones shown in the figures below. If the model and simulation are mismatched, tweak the model parameters until you get a good match. The better your model, the better the resulting controller.
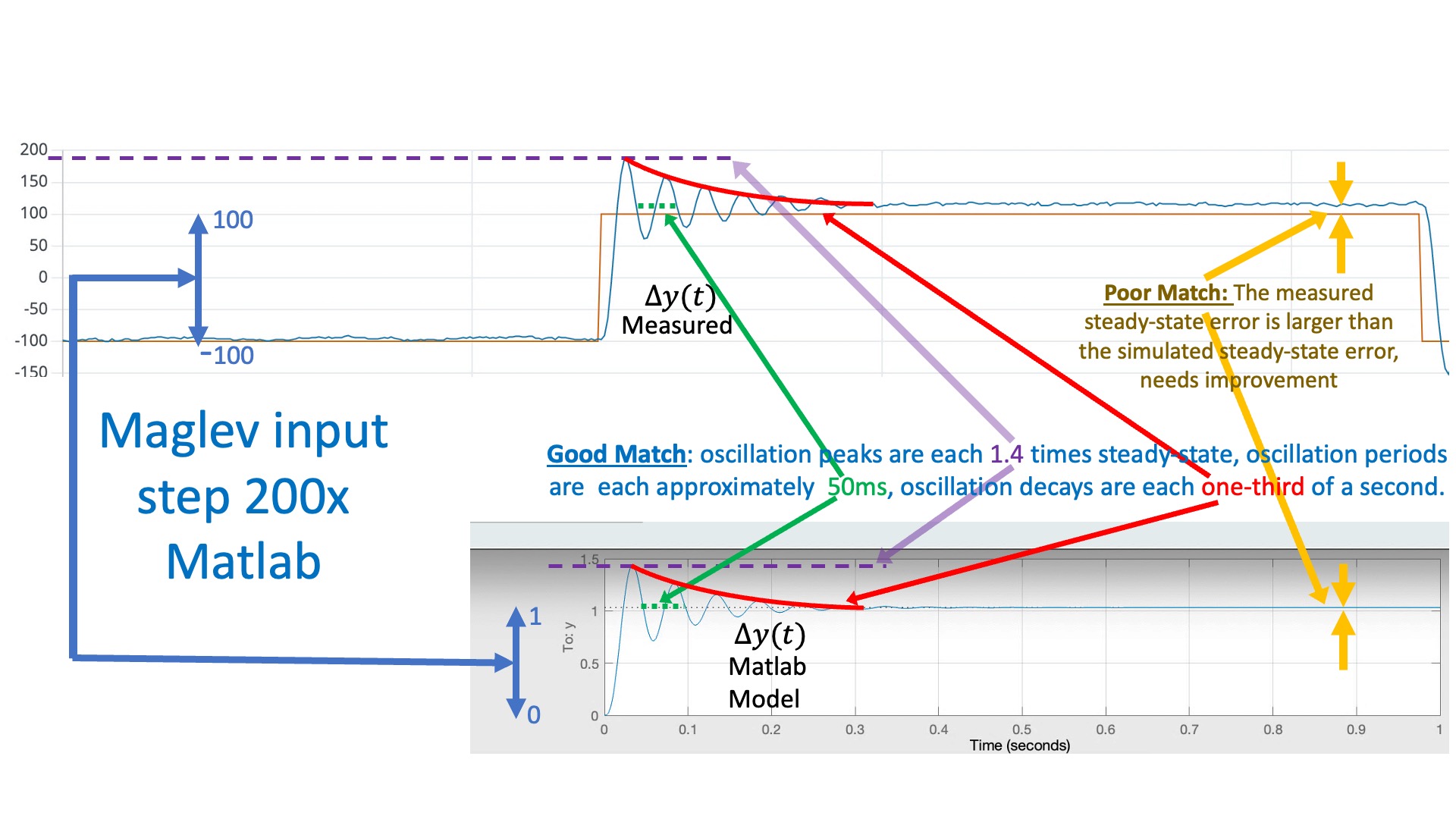
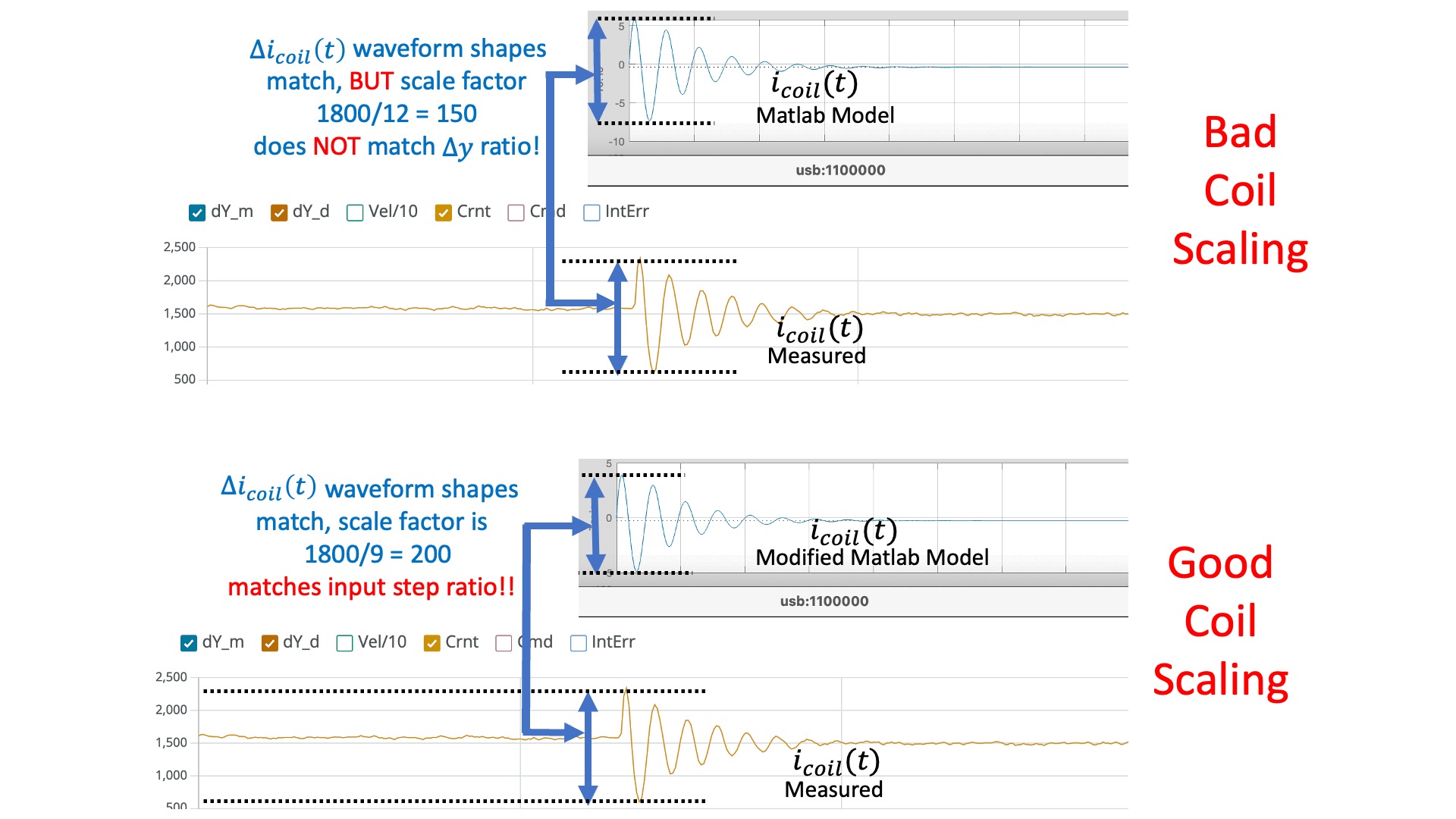
In the figure above, we compare the simulated and measured umbrella position, to check that they have the same "shape" (initial overshoot, oscillation period, oscillation decay time). Note that there is a scale factor between the plots that reflects a scale factor in step size. The script is using a "unit step", but when we set the square wave amplitude to 0.1 in the Teensy sketch, we can see (from the red y_d plot) that we generate a step of 200 (-100 to +100) in the units of the serial plotter. So the measured step is 200 times larger than the simulation (again in the plotting units).
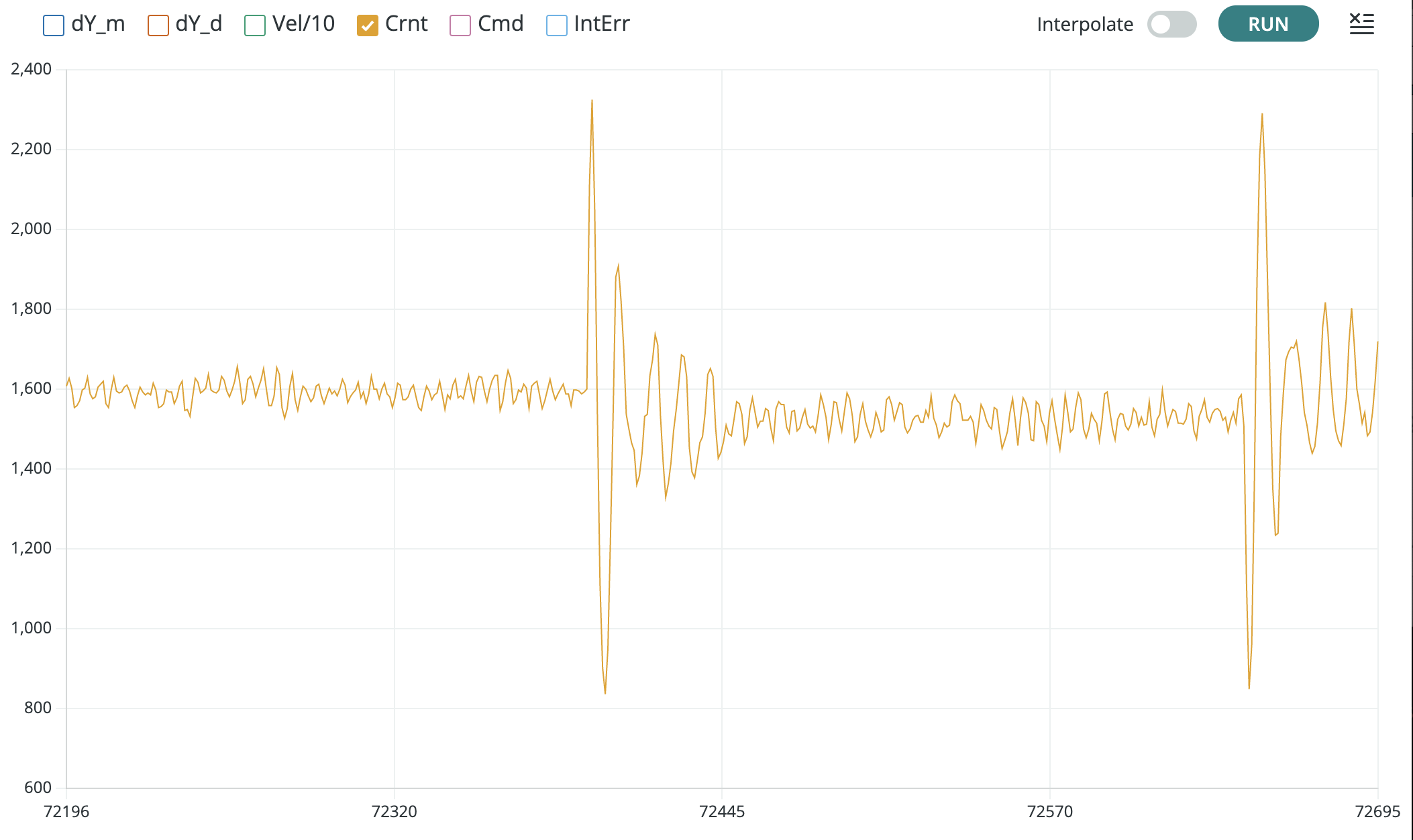
When comparing coil currents, as in the figure below, there should be the same scale factor of 200. So the measured current should have the same shape as the simulation, and should be 200 times larger.
Mismatched scale factors between measurement and model are BAAADDDD! If the scaling is not consistent in the model, then when you use that model to compute state feedback gains, those gains will be incorrectly scaled. And with incorrectly scaled gains, chances are your feedback system will be UNSTABLE!
DEBUG TIPS: If your coil scale factor is off, you may need to slightly adjust \gamma_{di/dc} to get the scale factor correct. If your ringing frequencyy in simulation doesn't match your measured frequency, you may need to slightly adjust \gamma.
Pole Placement
By providing feedback on all of the states of a plant, state-space controllers can offer significant performance improvements over what can be achieved with PID controllers. However, to realize these potential improvements, we must choose a gain for each state variable in the state vector x.
As you saw in the prelab, we can easily solve simple second order systems "on paper" and find gains that place the eigenvalues wherever we like (subject to a few constraints such as avoiding repeated eigenvalues). For larger systems, beyond third order, there is no closed form for the eigenvalues, and finding the gains for a given placement is best done computationally. We can rely on numerical approaches for determining K given \textbf{A} and \textbf{B}, such as Ackerman's method and its variants. Matlab/Python's place command does exactly what we want, provided we do not try to place poles right on top of each other,
% Example of place command in Matlab
p = [-1 -1.23 -5.0]; % poles must be unique
K = place(A,B,p)
Unfortunately, even though we have a function that will take desired eigenvalues (aka poles) and return the needed gains, that does not mean we can just set the closed-loop eigenvalues to be real and put them at -\infty. If we could, then our system would respond infinitely quickly to changes in desired position, and who wouldn't want that?
What happens when we make the poles too negative? What physical limitations stop us from choosing arbitrarily negative poles?
Use the pole-placement algorithm to find gains (K) as described in the following checkoff
and then implement your "best" result with your maglev hardware.
You can use the winPlaceShow_24.m script to run the pole-placement algorithm by
fixing all of the TODO: (Checkoff 3) sections and then uncommenting the appropriate line so that you are using Kplace code to select K.
When transferring the K's you compute with the script to the Teensy sketch, we STRONGLY recommend that you copy the gains from the script to the offset values in the sketch (lines 32, 33, 34, 38 and 39), and then upload. Trying to set four values using four different indexes from the send window in the serial plotter is too error prone.
Setting Gains with Pole Placement
END OF ASSIGNMENT FOR WEEK A
Links
Using LQR
The pole-placement algorithm allows us to choose gains K to set the closed-loop poles anywhere we please. However, if the resulting performance has problems (e.g., if convergence is too slow or if the required commands are too large), it is not always obvious how to change the poles to improve performance. This issue can be addressed by using the LQR algorithm, which specifies gains using a different set of parameters.
We strongly recommend you review section 3.1 in the "State Space And LQR" question on the prelab here.
Use the LQR algorithm to find gains (K) as described in the following checkoff and then implement your "best" result with your maglev hardware. You can use the new week B Matlab/Python to run the LQR algorithm by fixing all of the TODOs. Note that some TODOs you can fill in using your code/values from week A. Go ahead and do this now. The other TODOs are labeled with which checkoff (4 or 5) they correspond to.
Setting Gains with LQR
Show a screenshot to demonstrate the performance that results when the velocity term in Q is reduced. How long does it take for the output y to get halfway to its final value. What values of Q and R did you use?
What values of Q and R did you use? Show a screenshot of the resulting performance.
Adding the Integral term while using LQR
Complete the Matlab/Python script so that it will use LQR to calculate the gains for the maglev model plus and extra state, the integral of the error. See the Prelab for more details about adding the integral term, and think carefully about what happens to K_r. NOTE THAT THE STATES ARE ORDERED DIFFERENTLY IN OUR IMPLEMENTATION THAN IN THE PRELAB.
Checkoff 5
So how will you set the weight on the integral term? You want it to go to its steady-state value quickly, like all the other states, but is the integral the same scale as the other states? Suppose a sudden disturbance displaces the umbrella a tenth of a millimeter in a millisecond. The measured error in \Delta y will also change by 0.01 in that same millisecond, but what about the integral of the position error? An error of 0.01 would have to persist for a 1000 milliseconds before the integral of the errors rises to 0.01. What does that say about the relative weights for these two states?
Once you have fixed your script, try computing state gains for all the states, including the integrator, using LQR. Once you have gains that result in good performance in simulation, test them on the maglev system (the integral gain is K_{int} in the Teensy sketch, or index 2 in the send window). Below are some senarios to try, be sure to test your system's disturbance rejection using extra magnets.
Integral Controller